This article is part of the sequence The Basics You Won’t Learn in the Basics aimed at eager people striving to gain a deeper understanding of programming and computer science.
In the past few weeks, we have discussed the different ways computers deal with binary numbers in order to represent the numbers we are used to see – positive, negative andreal. This time, we will take a step back from diving in the details of how the hardware deals with such issues and focus on how the design decisions, taken by computer architects, affect the way we represent data in our code. Particularly, we shall explore the different “features” that data types, that we use in our code, have hidden for us.
Types of data in our programs
We all come from a different background. Some of us are used to dealing with scripting languages like JavaScript or Python, while others are more used to compiled languages such as Java or C#. Whatever the case, we all deal with different data types even if they are hidden by a subtle keyword such as “var”. Generally, data types fall into these categories:
- Integer numbers
- Floating point numbers
- Characters, text, booleans (all of these are actually aliases of integer numbers, although we categorize them differently due to their applications)
- Complex data types (structures and classes)
Even though we differentiate between those types, at the lowest level they are just zeroes and ones. Now, let us explore some subtle mechanisms of these data types. For the sake of simplicity, we will choose the C# programming language for our examples as it is most appropriate for the examples I am about to show in this article.
Furthermore, I want to mention that complex types are simply a set of primitive data types (as the ones we will explore in this article) so they are not that interesting in this context and we will not explore them.
Integer Numbers
Integer numbers are those which can either be positive, negative or zero, but they cannot be fractional. That is, they cannot have a decimal point to represent 5.6 for example. However, despite that integer numbers all have the same properties, they fall into different categories because of the difference in their size and sign.
Effect on the size
In our language of choice (C#), integers fall into these four basic categories – byte, short, int, long. All of these data types represent whole numbers, but they differ in the range of values available to the programmer. However, these ranges aren’t randomly defined. They actually correspond to 8 bit, 16 bit, 32 bit and 64 bit integers.
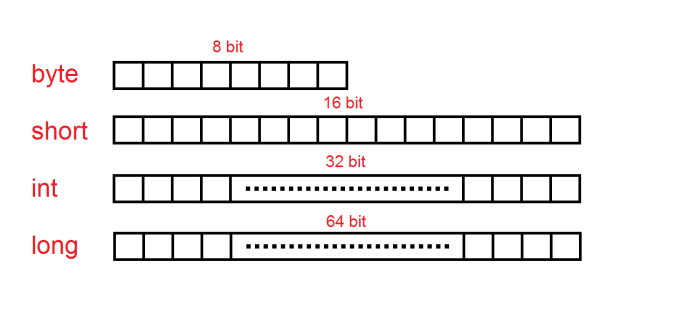
In most programming text books I have encountered, the ranges are expressed as whole numbers. For example, the byte data type has a range of [0, 256). But why is the range chosen that way?
Well, in the picture above you can see that a byte is an 8 bit number. An 8 bit number can be represented as a sequence of 8 boxes containing a 1 or a 0. That means that in each box you can store one of two values. If we want to compute the count of all the values we could represent in 8 boxes, we take 2 values for the first box, multiply it by the 2 values for the second box, multiply it by 2 values for the third box and so on. In the end, we get 2 * 2 * 2 * 2 * 2 * 2 * 2 * 2, which can be more easily written as 2 to the power of 8 (2^8), which is 256.
This principle applies for any other kind of integer numbers. We take 2 to the power of the count of the bits in that data type and we get the amount of values it can represent.
You might have noticed that the maximum value we can represent in a byte is 255, not 256. That is because we have to represent the 0 value as well.
Overflow and underflow
What happens when you perform a set of operations and result in a value which is higher than the maximum value you can store in a data type? This code demonstrates the case:
byte num = 255;
// Overflow. 255 + 2 = 0 + 1 = 1;
num += 2;
Console.WriteLine(num);
The result from this program is 1. This event is called overflow and is a natural outcome of the binary nature of the numbers in a computer.
Imagine that you have a 4 bit data type and you store the binary value 1111 in it. For simplicity, let’s assume that the number is unsigned (non-negative, we will elaborate more on this in the following section). That is the value 15, which is the maximum value we could store in a 4 bit data type (2^4 = 16). If we add 1 to this number, we get the binary result 10000, but since we only have 4 bits in which to store the result, we discard the leftmost part of it. The result is 0.
So, in conclusion, when you overflow an integer, it continues the operation from the minimum value you could represent in it. The symmetrical event is called underflow and it happens when you bypass the minimum value of the data type. Then, similarly, you get the maximum value.
One widely used solution to this is using a larger data type (such as int or long) and it works perfectly well in simple applications or competitive programming. But when developing an application which is sensitive in terms of memory (such as an embedded application), we should carefully analyze the requirements of the task and choose the most appropriate data type.
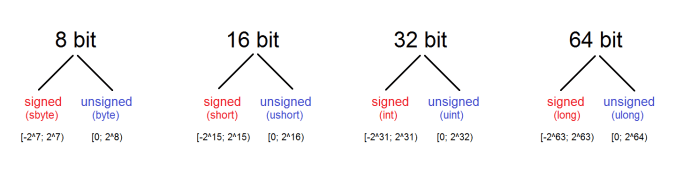
Effect on the sign
Another common outcome of the binary nature of numbers occurs when we want to represent negative values in an integer number. As mentioned in the negative binary numbers article, whenever we want to represent negative values, we use the leftmost bit to indicate whether the value is positive or negative. Due to that, we now have 7 bits left for the actual value of the number (For 8 bit numbers). Hence, we are left with 2^7, or 128 possible values for the positive part of the data type (but we should take into account the zero as well) and 128 values for the negative one. Therefore, every integer data type branches out to a signed and an unsigned variant. Unsigned types can represent positive values and zero. Signed types can represent both positive and negative values (and zero).
Floating point types
Another decent part of the data in our applications is real numbers, which are represented as floating point. In my last article, I explained how these data types work and I showed some examples which demonstrate some peculiarities when working with them. In this article I shall only review them.
Whenever we compare floating point numbers, we should use an epsilon value which serves as a threshold for indicating whether two numbers are equal.
abs(a-b) < epsilon
Another common issue is performing operations on numbers which are too far apart in terms of value. Last time, I showed an example where adding 0.01 and 1,000,000 results in 1,000,000.
When aiming for higher precision, we can use a higher precision floating point number (such as double). But if we are very serious about our computations (when developing financial applications, for example), we should choose a more complex data type. The decimal data type in C# for example. It is a floating point type using the decimal numeral system, instead of the binary one. Read on here.
However, when performance is a priority (3D rendering software for example) we could just stick with the float data type.
Characters and text
The character is another commonly used data type. I mentioned that every kind of data in our programs is represented by numbers in some way. But while you are reading this article, you see characters and text. So how do characters map to numbers in memory?
Special kinds of tables, called character sets, are defined for this issue. Their sole purpose is to map characters to numbers. ASCII is one of the most famous character sets.
So the character ‘a’, which is shown on the screen, is actually represented by the integer 97 in memory. The operating system takes this integer and knows that it should send commands to the display to turn on the corresponding pixels which represent the letter ‘a’. ASCII, unfortunately, can represent up to 128 values and its extended version – up to 256. (Can you guess why it has this range?)
Unicode is a more sophisticated character set, which can represent a lot more different symbols. That is enough to cover all the different characters out there. Unfortunately, different character sets have different requirements in terms of how they are actually stored in memory. We shall discuss this topic in the next article on these series.
Representing text
Text, as you might guess, is just a sequence of characters. In different programming languages, however, the way to represent this is different. In high level programming languages, text (we tend to call it a string) is actually not a primitive data type but an object. A common problem of a string is that we should somehow determine what its length is. If we just have a sequence of regular characters in memory, we won’t be able to determine where a string ends. There are two approaches to this issue.
The first one is to treat the string as a complex object (object-oriented programming). So, in an object, we store the array of characters, which is the actual content and we keep another integer variable for the length. This approach allows us to define some useful utilities for dealing with strings in the class definition itself.
Another approach (used in C) is to store the string as an array of characters. But in order to determine where the string ends, we need to allocate an additional element at the end of the array. That element is used to “terminate” the string. Usually, that is a character with the ASCII value of zero. This approach makes the work of the developer harder, but it grants them more freedom. For example, one of the greatest benefits of this approach is that you can easily manipulate the characters in the string without allocating additional memory.
Strings in Java and C#, on the other hand, are immutable (C++ strings are mutable, though). Once created, you cannot change them.
Character arithmetic
So in the end, it seems that characters are simply integer numbers. The size of this data type, however, varies in different programming languages. In C# and Java, characters take up 16 bits in order to be able to easily store Unicode values. In C and C++, however, characters are 8 bit data types. So if you want to use Unicode characters in C or C++, you should consider some kind of non-standard utility.
But since characters are just numbers, that means they support all the regular integer operations. This property of characters is widely used in various applications. One of the simplest use cases is to print the characters from the English alphabet. Here is a C# program that performs that:
char ch = 'a';
while (ch <= 'z')
{
Console.WriteLine(ch);
// integer operations can be used on characters
++ch;
}
Another very useful property of characters is that they can be easily mapped to some kind of index. Look at the ASCII table I linked above and notice how the character ‘5’ maps to the value 53. This isn’t the integer value of 5, but the character ‘5’. But if we want to actually get the integer value of 5, we can just subtract the value of the character ‘0’, which is 48 and we get the correct result. However, instead of hard-coding the value 48 in our code, we could simply subtract the character ‘0’ itself:
char five = '5';
int fiveAsInt = five - '0';
Console.WriteLine(fiveAsInt);
A sample task
One of my favorite tasks, concerning character arithmetic is to count the occurrences of all the characters in a text. A naive approach to this problem would be to use a Dictionary in C# (HashMap in Java, unordered_map in C++). Then store the occurrences as character-integer key-value pairs in the form – letter : occurrence.
But maintaining a Dictionary has its overhead and a more efficient approach is to actually take advantage of the character arithmetic properties. You can map letters from the alphabet to indices in an array by simply subtracting the character value of ‘a’. Here is a sample program that performs this algorithm:
const int alphabetLength = ('z' - 'a') + 1;
string text =
"the quick brown fox jumps over the lazy dog";
int[] occurences = new int[alphabetLength];
char ch;
for (int i = 0; i < text.Length; ++i) { ch = text[i]; if (ch >= 'a' && ch <= 'z')
{
occurences[ch - 'a']++;
}
}
for (int i = 0; i < alphabetLength; ++i) { Console.WriteLine("{0} --> {1}",
(char)(i + 'a'),
occurences[i]);
}
This program, however, works only for text with lowercase letters. Can you think of a way to handle uppercase letters as well? And no, don’t use the ToLower and ToUpper string methods available in high-level languages. Think in terms of character arithmetic.
Character arithmetic could be a very powerful tool if used efficiently and now you understand how it works. You can quickly master this skill with a bit of experimentation. The rest is up to you, young padawan.
Conclusion
The binary nature of data in computers has its effect on our work as developers. I believe that every professional should have an understanding of data types and binary numbers in general. The “features” mentioned in this article could be a huge obstacle to the unwary developer, but could also be powerful instruments in the hands of the skillful programmer.
Next time, we will explore more thoroughly the topic of character sets and how they are stored in memory.