This article is part of the sequence The Basics You Won’t Learn in the Basics aimed at eager people striving to gain a deeper understanding of programming and computer science.
When I wrote my first program, my trainer told me I merely wrote the source code. Now, I have to translate it to a language understandable by computers. We call that compilation. It happens by clicking Ctrl+F5 (In Visual Studio). And there you have it, your program is now an executable.
That’s how they initially thought me what the build process of a program is. And that is a good enough explanation for beginners. But at one point, I realized that when I click Ctrl+F5, some processes happen behind the scenes which we don’t see. Those processes we will explore in today’s article.
And did you know, that when you click Ctrl+F5, the processes used are different for different languages? Have you ever wondered why is it harder to code in C++ than it is in C#?
Well, we won’t be able to explore the whole details of the last question. That has a lot to do with language design and the decisions being taken during the years. But we will explore the fundamental difference between those languages. That difference lies in their build process.
Languages compiled to native code
The most popular examples of such languages are C and C++.
What does compiling to native code means?
When we build our program, the code goes through various stages and in the end, is transformed to machine code. That’s code which the processor executes directly. More on the subject, check out one of the previous articles in the series.
That’s the high-level view. But let’s take a sneak peak in the internal process of transforming source code into machine code.
For this purpose, we will explore the process of building C and C++ programs, as they are the most popular languages using this approach.
The whole process includes 4 steps – Preprocessing, Compilation, Assembly, Linking.
Preprocessing
In C and C++ programs, there are some lines, called preprocessor directives, which begin with a #.
The preprocessor uses those directives to manipulate the text of the program in some way. For example, there is a #include directive. When the preprocessor sees it, it takes the contents of the file specified by it and substitutes it on the line the directive was first seen. We use this in order to reuse code instead of copy-pasting it in different files.
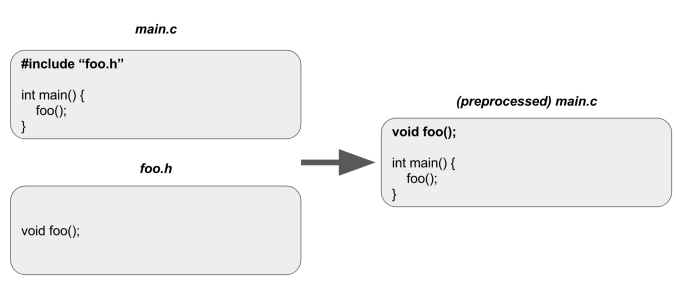
There are other directives as well, but we won’t explore them in this article. In general, the preprocessor transforms the initial source code into preprocessed code with all the text transformations applied. Of course, the result is stored in a temporary file and does not overwrite the original file. That file is further used in the compilation step.
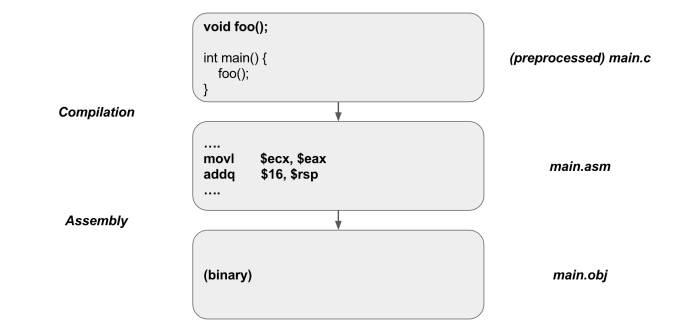
Compilation & Assembly
In this step, the preprocessed code is further transformed into assembly.
Then, another program comes into play, called the assembler. It’s purpose is to transform assembly code to machine code. (What’s assembly and how it works? Check out this again.)
There is a possibility for the assembly step to be skipped, as some compilers might directly translate your source code into machine code. But even so, that would mean that the compiler has an embedded assembler in it. So the step just might be implicit, but it is still there.
The resulting machine code is packed into an intermediate file called an object file. Those files contain all the data from a single source file. But as you know, there might be multiple source files in a single program. That means that an object file by itself is not enough to complete a whole program. There comes the final step, called linking.
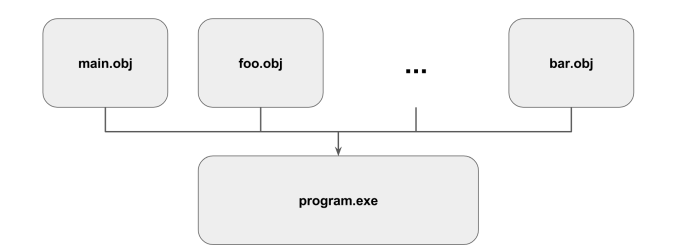
Linking
Now you have a dozen of object files in your project. Those are the separate blocks of the program. The final linking stage is when those blocks are combined into a single executable file. This is also the stage where the various dependencies between files are resolved.
For example, if file A invokes a function in file B, you will have instructions in the object file of file A to call that function. But the instructions of the function is not present in the same object file. The Linker is the one responsible for checking if that function actually exists in any other object file of the program. In this case, file B.
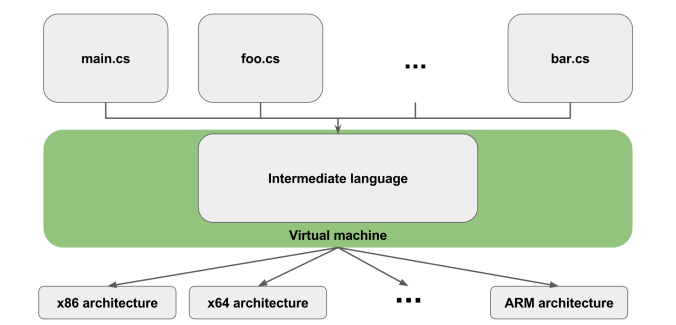
Virtual machine based Languages
The most popular languages in this bracket are Java and C#.
These languages don’t directly compile to native code for the specific hardware. Instead, they compile to an intermediate language, which is executed by a virtual machine.
A virtual machine is like an emulated computer on top of your computer. It’s purpose, in our case, is to execute the intermediate code generated. The way it executes it is by understanding what is the type of hardware it runs on and given that information to further compile it to the native code of the machine.
The idea of this process is to build your program once for an abstract virtual machine and it is the VM’s job to understand what is the actual hardware running underneath. This way, you gain platform-independence.
We saw that when building programs compiled to native code (particularly C and C++), we go through several processes.
But in these languages, the whole build process is limited to the compilation of the source files to intermediate language files. The process of converting those files to the native code of the computer is the job of the virtual machine.
Interpreted Languages
Popular examples here are JavaScript, Python, Ruby, etc.
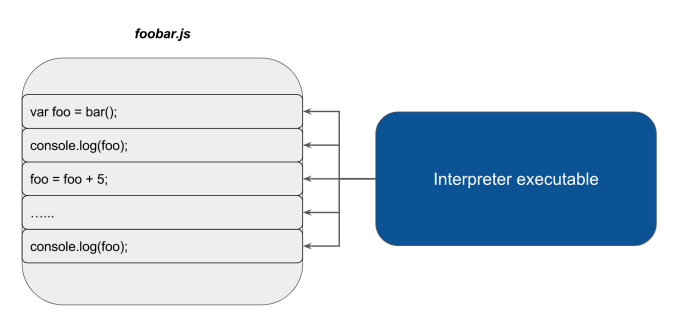
These lack compilation at all. The way programs written in these languages get executed is by having a separate program, called the interpreter. It executes the instructions in them line by line. In comparison, compiled languages’ the source code is analyzed and executed as a whole unit, while in interpreted languages that is done line by line.
That means that you can execute half of the program before getting an error, while in other languages, one error is enough to prevent the execution of the whole program (given that it is a compilation error, of course).
Can every language be compiled/interpreted?
In the first revision of this article, some people cleverly pointed out that some of the languages which are interpreted, can be compiled as well. And vice versa.
So to answer the query – Yes, every language that can be interpreted and every language can be compiled. And to understand that, we first have to more deeply understand what exactly is compilation and interpretation.
Compilation means I want to translate language X to language Y, which if run will give the same result as language X, but faster.
Interpretation means take this program, written in language X and execute the rules, defined by that language. A fancy way of saying, running this program.
So in essence, both compilation and interpretation mean to make a transformation of a language. That is why, every language which can be compiled, can be interpreted as well.
However, the reason why some languages are called compiled and others interpreted is because those languages are traditionally used with that process and their rules are optimized for that process.
For example, the compilation of a C++ program is a slow process, which can lead to a great increase of performance when compiled. But if interpreted, those same rules will cause the program to run much slower.
On the other hand, a program written in an interpreted language has rules which make it easy to be interpreted fast, but won’t cause a great benefit in terms of performance if it is instead compiled. For example, a transformation of a JavaScript program to another language can hardly cause any increase in performance.
There are exceptions to the above statement, of course, as there are various modern tricks which allow you do to gain some benefits of compilation (like JIT compilation), but in their traditional form, those languages are not suited to be compiled.
So why choose one instead of the other?
We have learned what different types of languages there are in terms of the build process. But now, let’s explore what’s the difference between them in terms of choosing the right language for doing our job.
Ease of coding
The first important aspect is whether writing in one language is easier than another. And writing in C or C++ is by far the hardest. I believe thatif you learn to program in C and C++, you can learn to program in any other language. The reason is that they are closest to the nature of the computer. Due to that, it’s further away from the nature of us humans.
On the other hand, writing in Java or C# is easier than writing in C or C++, because they get compiled to intermediate language which is a higher level of abstraction than native code. Also, the aid of a virtual machine gives us the benefit of better error handling, garbage collection and other features, which help us write safer code.
And interpreted languages are an even higher level of abstraction allowing you to achieve a lot more with less code.
Portability
A great concern in computer science is whether your program can run on many platforms. This is not the case for languages compiled to native code, as the resulting code is specific to the hardware the program is built for. If you want your C program to run on Windows and Linux, you will have to recompile it twice for the different platforms. And if it uses platform-specific instructions, then it will be even harder to maintain that program.
On the other hand, the virtual machine’s purpose in Java and C# is to know what is the underlying hardware and to further compile the code to the platform-specific machine code. Programs written in Python or JavaScript can also run on any machine as long as there is an interpreter that supports those languages on it.
Performance
This is the area in which programs, compiling to native code excel at. They don’t have the overhead of starting a huge virtual machine or running a several megabyte interpreter. They just run.
However, just writing your program in C doesn’t mean it’s going to be faster than virtual machine based languages. Java developers have the benefit of the virtual machine optimizing the code run-time. When writing your program in C, it is your duty to optimize your program yourself. Of course, the compiler will do much of that job for you, but in some circumstances, that may not be enough.
For example, if you compile your Java program and it runs on a quad core processor, the virtual machine might detect that and optimize your program accordingly. That is of course, given that you are creating a multi-threaded program. For example, if you mark several functions to be executed asynchronously, the JVM can decide what is the optimal amount of threads which can be used given that you have a quad code processor.
In C, you have to do the leg work yourself and write specific instructions for making use of the quad core processor.
So in the end, low-level programming languages like C and C++ give you the freedom to optimize your program, but it is still your job to do that.
Memory
C and C++ are winners here as well. Again, there is an overhead in terms of memory when running the virtual machine or the interpreter.
This might not be an issue for server machines, but it is an important constraint of embedded devices. For example, if you want to program your micro-controller with an external memory of 8 KB in Python, you will first have to embed the 2 MB Python interpreter on the device.
As for the virtual machine type of languages, there are versions which are more minimalistic and designed for embedded environments, but languages compiled to native code still beat them in terms of memory usage.
Conclusion
Now you understand the basics of what’s the build process of the programs we write.
In Sum. There are three types of languages in terms of the build process. Those that compile to native code. Those compiled to intermediate language code, or virtual machine code. And those that are interpreted.
Also, given this brief overview, we learned why some languages are faster than others and why we choose different languages for different purposes.
Next time, we will delve again into the internals of our programs, by exploring what is a stack and a heap and how our programs use them.