This article is part of the sequence The Basics You Won’t Learn in the Basics aimed at eager people striving to gain a deeper understanding of programming and computer science.
Hey, it has been a while since I last wrote an article on these series. Last time, we covered negative binary numbers and the different ways of representing them in a computer. This time, we will explain how to deal with real numbers. More specifically, we will briefly discuss fixed point numbers and then we will move on to the core of this article – floating point numbers.
But how do we express values of real numbers?
In a previous article, we discussed how to represent values written in the decimal numeral system. Given 123, it equals:
1 * 100 + 2 * 10 + 3 * 1
Or this could be written as:
1 * 10^2 + 2* 10^1 + 3 * 10^0
so we take 10 to the power of the position of the current digit.
But how do we apply this technique to numbers with a decimal point (123.456 for example)?
Well, recall that a number raised to a negative power results in 1 divided by that number raised to the positive power. In other words:
6^(-1) = 1/(6^1)
Given that, we could indicate the positions after the decimal point as negative. That would mean that we could raise the corresponding digit to a negative power of ten.
So 123.456 can be represented as:
1 * 100 +
2 * 10 +
3 * 1 +
4 / 10 +
5 / 100 +
6 / 1000
OR
1 * 10^2 +
2 * 10^1 +
3 * 10^0 +
4 * 10^(-1) +
5 * 10^(-2) +
6 * 10^(-3)
That is how we express real numbers in the decimal numeral system. But we know that the same rules apply to binary numbers as well. We just change the base from 10 to 2.
So 101.11 (5.75 in decimal) is expressed as:
1 * 2^2 +
0 * 2^1 +
1 * 2^0 +
1 * 2^(-1) +
1 * 2^(-2)
Now that solves the issue of expressing real number values in binary. But how do we store them in memory?
Fixed point representation
A first approach would be to have a fixed decimal point somewhere in the number and whatever interprets our number should know where it is. That is actually called fixed point representation.

Whenever we want to perform operations with this format, we just apply the same approach as we would for integers. Except that we have the knowledge of the decimal point and where it is positioned in the number. For example, if we want to have an 8 bit fixed point number, we could have 4 bits for the integral part and 4 bits for the fractional part. Since we can apply the same operations as on integers, then this data type has no loss of accuracy. Except, of course, for the usual suspects of overflow and underflow.
However, the big drawback of the fixed point data type is that it has a very short range of available values. For comparison, an 8 bit integer can represent values up to 255, while an 8 bit fixed point fraction – up to 15.9375 (15 + 15/16).
Due to this drawback, fixed point data types are not common in most programs. They do find application in some financial software, however. In that field accuracy is a necessity.
Scientific notation
Another approach for representing real numbers in computers is using floating point notation. It uses the idea of scientific notation you probably encountered in school.
Let’s say you want to represent some huge number like 135,243,000,000,000. It might be tedious to write all those digits down and actually count the exact number of the zeroes at the end of the number. That is why you can represent this number using the following format:
1.35243 * 10^14
Recall that each time you multiply a number by 10, you just move the decimal point to the right: 1.23 * 10 = 12.3
So multiplying a number by 10 raised to the 14th power means that you should move the decimal point 14 times to the right. That way, you will get that huge initial number I first wrote.
Much more convenient right? That is actually scientific notation and it is used whenever you want to represent a very big or a very small number in mathematics.
Note however that 1.35243 * 10^14 is the same as 13.5243 * 10^13 which is the same as 135.243 * 10^12 and so on…
We have numerous ways of representing the same number in this notation. That is why, some smart people stated that there could be only one digit to the left of the decimal point and it cannot be zero. Which means that the only correct expression of the above mentioned is 1.35243 * 10^14. That expression is called normalized scientific notation. All the rest are called denormalized.
Now, some terminology which would come in handy later on. The different parts of this notation have a very mathy naming.
The most meaningful part of the number (1.35243 in our case) is called the mantissa. Some refer to it as significand as well.
The power to which 10 is raised (14 in our case) is called the exponent.
The sign of the number is called… well, the sign. It indicates whether we are dealing with a positive or a negative number.
Floating point representation
The alternative of the scientific notation in terms of computing is the floating point notation. The only difference is that it is used in binary and not in decimal. (But there are decimal floating point numbers in programming as well. The System.Decimal type is C# is such an example. Read on here)
So floating point numbers consist of the exact three things I mentioned earlier – sign, mantissa and exponent. These three parts are packed in a single spot in memory. The most common implementations of floating point numbers in programming languages use 32 bits (these are called single precision floating point numbers, also known as float) and 64 bits (called double precision floating point numbers or simply double).
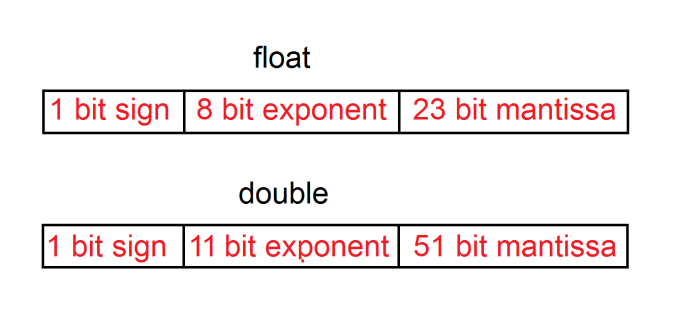
The sign bit shows whether the number is positive or negative. 0 – positive, 1 – negative.
The mantissa stores the value which is to be shifted by the exponent. There is a neat trick here, though. I mentioned that there should be only one digit to the left of the decimal point and it should be non-zero if the number is to be considered normalized. Well, the only digit different than zero in binary is 1, so that means it could be made implicit (in other words – not present at all!).
The exponent represents the power to which 2 is raised. When we use scientific notation in binary, we use 2 as it is the base of the numeral system. Multiplying by 2 in binary is the equivalent of multiplying by 10 in decimal – it shifts the decimal point to the right. When the exponent is calculated, however, a number is subtracted from its value. That is because we want to have the possibility of representing negative powers as well. The exponent in 32 bit floats, for example, uses 8 bits. Whenever it is used, we first subtract 127 from it in order to be able to represent values from the range [-127; 127).
Everything I mentioned, could be summed up in this expression:

Some details
Wait, if there is always an implicit 1 in the representation of floating point numbers, how do we represent a zero?
Good question! There are some special cases in the representation of floating point numbers and one of them is zero. Whenever we want to represent a number using the expression I showed previously, the exponent should be in the range (for floats atleast) [1; 255). That means that the values 0 and 255 are reserved for special cases. These special cases include zero, positive infinity, negative infinity, not a number (NaN) and some other variations which are out of scope for this article.
The following calculations result in these special values.
Non-zero positive number / 0 = Positive infinity (+Inf)
Non-zero negative number / 0 = Negative infinity (-Inf)
0 / 0 = Not a number (NaN)
Benefits
The power of this notation is that it can represent very large numbers and very small numbers alike.
If we use a 32 bit float, for example, the maximum number we could represent is:
1.11111111111111111111111(binary) * 2^127
that equals approximately 3.402823466 * 10^38. That’s a number with 39 digits! In contrast, the number of digits you could represent by a 64 bit integer is up to 20.
The minimum is
-1.00000000000000000000000(binary) * 2^126
or approximately -1.175494351 * 10^38.
Note: These examples are taken from the book Code: The hidden language of computer hardware and software
This is why floating point numbers are widely adopted in modern computing. But there are some pitfalls you might encounter when dealing with them as well.
Drawbacks
Probably the most popular one is comparing floating point numbers.
When you store a value such as 5.1, for example, it might be stored as 5.0999523591 in memory. And if you compare that value to something which is 5.1 it will return false. That is why we shouldn’t directly compare floating point numbers with the == operator.
This sample code in C# demonstrates this abnormality:
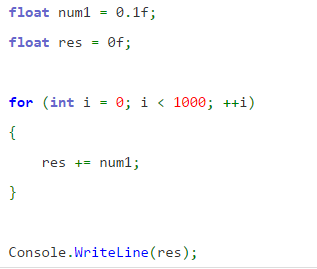
0.1 summed up 1000 times normally equals 100. But on my machine, after I run this code snippet it outputs 99.99905.
This actually shows another pitfall with floating point numbers which occurs when adding a lot of floating point numbers together. But we will discuss this in another article.
The simplest solution for comparing floating point numbers is to use some very small value which would be a threshold for indicating whether two numbers are equal. The mathy way of naming that value is epsilon. So we could write a routine like this for comparing two floating point numbers a and b:
abs(a – b) < epsilon
Another common pitfall when working with floating point numbers is performing operations on numbers with a big difference in the value of the exponent.
Let’s say we want to calculate 1.23 * 10^3 + 3.56 * 10^1. Well, we can’t directly add up the values of the numbers, we first have to match up their exponents. So essentially, we have to calculate 123 * 10^1 + 3.56 * 10^1. This time, we can easily add up the mantissa of the two numbers and normalize the result later on. But whenever we do such transformations on floating point numbers, we could get a number which cannot fit in the provided space. In that case, the only thing we can do is remove the least significant information.
So if we add 10000 and 0.0001 we get 10000.0001. But if we can’t afford to keep the whole number as it is, we have to remove some data from it. Well, in this situation we would obviously prefer removing the 1 in the rightmost part of the number. Given this, try out this program in C# (or whatever language you prefer):

When we add 0.01 to 1,000,000 ten thousand times, the result is 1,000,000. That won’t be so cool if this happens to be the balance of some rich guy, right?
The brute-force solution for dealing with these problems is using a double precision floating point number (64 bits), but that would have similar behavior at some point, due to its floating point nature.
Conclusion
Floating point numbers serves us a great bit when representing real numbers. In fact, floating point arithmetic is considered so important, that processors nowadays have an embedded FPU (Floating Point Unit) in them. But whenever we deal with such numbers, we should proceed with caution as there are some pitfalls we could fall into. Furthermore, such arithmetic is not appropriate for financial software. In that case, fixed point arithmetic or a more sophisticated decimal floating point arithmetic is preferred.
This article concludes the mini-series on binary numbers. Next up, we will discuss how everything we have learned about binary numbers affects the data types we use in our programs.